What are the current state and key challenges of Feature Store Service in MLOps?
Understanding the current state and key challenges of Feature Store Service in MLOps.
Background
Data scientists and Machine Learning Engineers spend a significant amount of their time creating training datasets for ML models. Building data pipelines to generate the features for training as well as for inference is a significant pain point. Developing and managing features is a critical piece of developing ML models. To standardize the process of building, storing, and managing features, we need a Feature Store Service.
Feature Store service
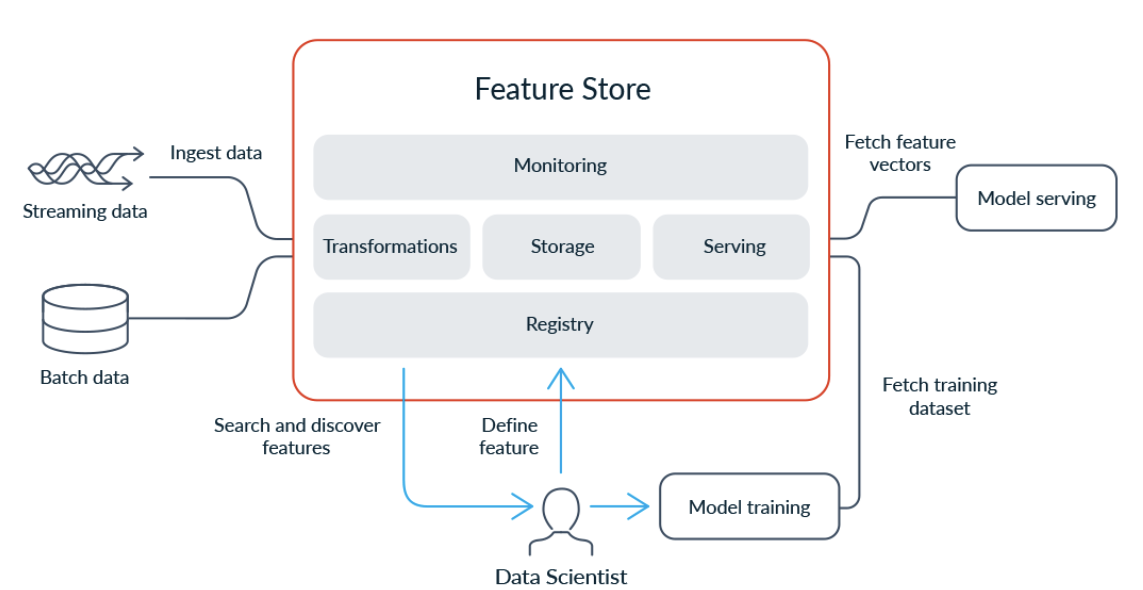
Feature store services are becoming increasingly popular: Uber’s Michelangelo, Apple’s Overton, Airbnb’s Zipline, Gojek’s Feast, Comcast’s Applied AI, Logical Clock’s Hopsworks, Netflix’s Fact Store, and Pinterest’s Galaxy are some of the popular open source examples of a feature store service. A good list of emerging feature stores is available at featurestore.org. From an architecture standpoint, there are 5 main components of a modern feature store: Transformation, Storage, Serving, Monitoring, and Feature Registry. You can learn more here.
Even though there are an increasing number of investments in this space. However, there are still some key challenges in building a Feature Store:
- Feature Versioning
- Data lineage (including integrations with data lineage systems)
- Data Quality Monitoring
- Automatic time travel capabilities
- CI/CD capabilities for managing the deployment of features
- Cost visibility into ML data pipelines
Let’s pick Data Lineage as an example, there are two common use cases:
- Handling PII and Regulatory compliance: let’s say Data team decides to delete a feature due to privacy concerns, how can this operation be cascaded into all downstream storage, and training pipelines currently using this feature.
- Updating a Feature with prior context: Most closely-related features are grouped together in a Feature Group. For example, both Age and Date of Birth are closely related to each other, and are likely stored in the same HR database. The same feature can be used in multiple Feature Groups, hence in multiple models. Let’s say the owner of model 1 decides to retrain one feature to help boost the accuracy of his model. He did this without the context that this feature exists in multiple other Feature groups which are currently being used in other models owned by another team. Which makes all the other model performance become worse.
At this moment, I haven’t found any good solutions to solve Data Lineage problems.
How about you? Do you use Feature Store at your current company? What are the problems you are facing? Let’s brainstorm together so we can solve all the interesting problems in this space.
Leave a comment