Airflow tutorial 1: Introduction to Apache Airflow
An introduction to Apache Airflow tutorial series
The goal of this video is to answer these two questions:
- What is Airflow?
- Use case & Why do we need Airflow?
What is Airflow?
- Airflow is a platform to programmaticaly author, schedule and monitor workflows or data pipelines.
What is a Workflow?
- a sequence of tasks
- started on a schedule or triggered by an event
- frequently used to handle big data processing pipelines
A typical workflows

- download data from source
- send data somewhere else to process
- Monitor when the process is completed
- Get the result and generate the report
- Send the report out by email
A traditional ETL approach
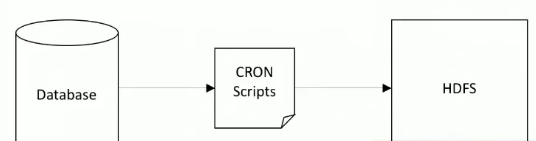
Example of a naive approach:
- Writing a script to pull data from database and send it to HDFS to process.
- Schedule the script as a cronjob.
Problems
- Failures:
- retry if failure happens (how many times? how often?)
- Monitoring:
- success or failure status, how long does the process runs?
- Dependencies:
- Data dependencies: upstream data is missing.
- Execution dependencies: job 2 runs after job 1 is finished.
- Scalability:
- there is no centralized scheduler between different cron machines.
- Deployment:
- deploy new changes constantly
- Process historic data:
- backfill/rerun historical data
Apache Airflow
- The project joined the Apache Software Foundation’s incubation program in 2016.
- A workflow (data-pipeline) management system developed by Airbnb
- A framework to define tasks & dependencies in python
- Executing, scheduling, distributing tasks accross worker nodes.
- View of present and past runs, logging feature
- Extensible through plugins
- Nice UI, possibility to define REST interface
- Interact well with database
- Used by more than 200 companies: Airbnb, Yahoo, Paypal, Intel, Stripe,…
Airflow DAG
- Workflow as a Directed Acyclic Graph (DAG) with multiple tasks which can be executed independently.
- Airflow DAGs are composed of Tasks.
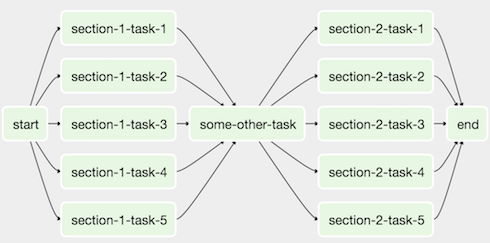
Demo
- http://localhost:8080/admin
What makes Airflow great?
- Can handle upstream/downstream dependencies gracefully (Example: upstream missing tables)
- Easy to reprocess historical jobs by date, or re-run for specific intervals
- Jobs can pass parameters to other jobs downstream
- Handle errors and failures gracefully. Automatically retry when a task fails.
- Ease of deployment of workflow changes (continuous integration)
- Integrations with a lot of infrastructure (Hive, Presto, Druid, AWS, Google cloud, etc)
- Data sensors to trigger a DAG when data arrives
- Job testing through airflow itself
- Accessibility of log files and other meta-data through the web GUI
- Implement trigger rules for tasks
- Monitoring all jobs status in real time + Email alerts
- Community support
Airflow applications
- Data warehousing: cleanse, organize, data quality check, and publish/stream data into our growing data warehouse
- Machine Learning: automate machine learning workflows
- Growth analytics: compute metrics around guest and host engagement as well as growth accounting
- Experimentation: compute A/B testing experimentation frameworks logic and aggregates
- Email targeting: apply rules to target and engage users through email campaigns
- Sessionization: compute clickstream and time spent datasets
- Search: compute search ranking related metrics
- Data infrastructure maintenance: database scrapes, folder cleanup, applying data retention policies, …
The Hierarchy of Data Science
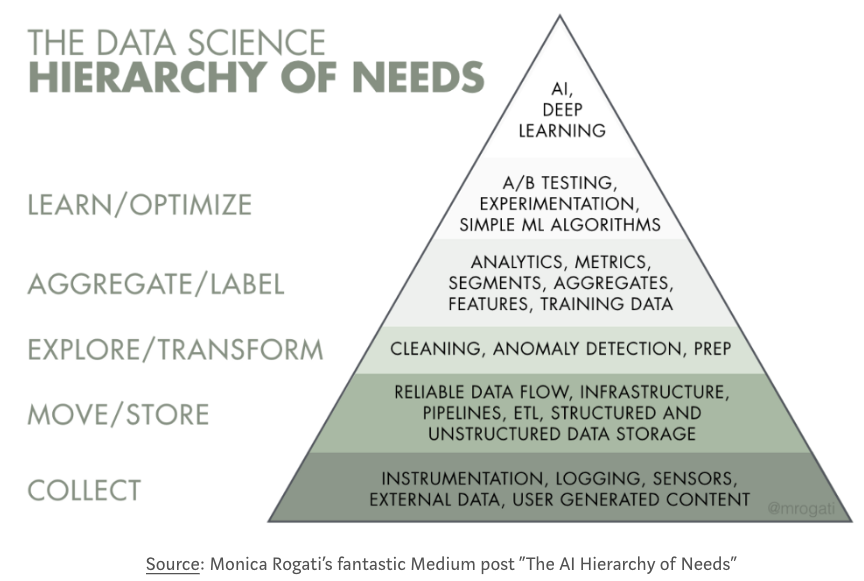
This framework puts things into perspective. Before a company can optimize the business more efficiently or build data products more intelligently, layers of foundational work need to be built first. Data is the fuel for all data products.
Unfortunately, most data science training program right now only focus on the top of the pyramid of knowledge. There is a discrepancy between the industry and the colleges or any data science training program. I hope this tutorial is helpful for anyone who tries to fill out the gap.
Leave a comment